puppeteer 实现爬虫
puppeteer 实现爬虫(windows)
因为puppeteer中大量api都是异步函数,所以首先需要对异步函数async/await有一定的了解,await会暂停当前async函数的执行,等待后面的Promise的计算结果返回以后再继续执行,也就是说程序会在这停止,直到到await后面的函数有返回才继续执行,但是前提是返回必须是一个Promise对象,也就是await只对函数有返回Promise对象时才进行等待,其他情况不进行等待。
①首先安装一下puppeteer
因为安装Chromium十分的慢浪费时间,所以建议跳过该步骤
npm i --save puppeteer --ignore-scripts
②手动安装Chromium
贴上下载网址:https://www.chrome64bit.com/index.php/chromium-64-bit-for-windows
下载时候安装之后就是一个文件夹。
③安装完成之后启用Chromium,这里headless控制是否弹出浏览器,executablePath,指定Chromium的安装位置
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch({
headless: false,
executablePath: 'C:\\Users\\lenovo\\AppData\\Local\\Chromium\\Application\\chrome.exe', //指定chromium浏览器位置;
});
④启用Chromium之后,访问百度图片网址,模拟搜索关键字并查询的操作,查询的时候起初使用的,page.click(‘selector’),模拟点击,但是发现click函数总是报Error: Node is either not visible or not an HTMLElement。
await page.click('.s_btn');

检查网页元素发现,按钮的display属性是none,因此获取不到
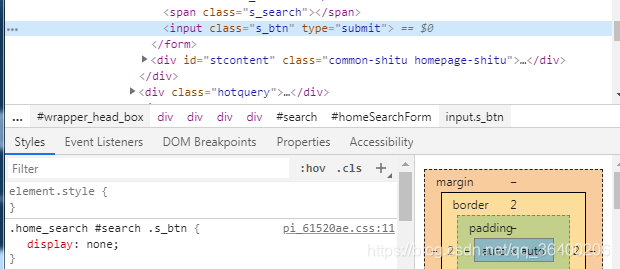
因此最后使用DOM的方法获取,利用的page.evaluate()方法。
await page.evaluate(() => {
document.querySelector('.s_btn').click()
});
⑤查询关键字之后,将网页中所有的img标签匹配,并获取图片的src地址,并交由srcToImg函数进行处理。代码如下所示。
const puppeteer = require('puppeteer');
const {mn} = require('../config/defualt');
const srcToImg = require('../helper/srcToImg');
(async () => {
const browser = await puppeteer.launch({
headless: false,
executablePath: 'C:\\Users\\lenovo\\AppData\\Local\\Chromium\\Application\\chrome.exe', //指定chromium浏览器位置;
});
const page = await browser.newPage();
await page.setViewport({width: 1000, height: 1000, deviceScaleFactor: 1,});
console.log('reset viewPort');
await page.goto('http://image.baidu.com/');
console.log("go to https://image.baidu.com/");
await page.focus('#kw');
await page.keyboard.sendCharacter("狗");
await page.evaluate(() => {
document.querySelector('.s_btn').click()
});
console.log('go to search list');
page.on('load', async () => {
console.log('page loading done, start fetch...');
const srcs = await page.evaluate(() => {
const image = document.querySelectorAll('img.main_img');
return Array.prototype.map.call(image, img => img.src)
});
srcs.forEach(src => {
srcToImg(src, mn);
});
console.log("finish");
await browser.close();
})
})()
⑥srcToImg函数具体实现
const fs = require('fs');
const {promisify} = require('util');
const http = require('http');
const https = require('https');
const path = require('path');
const writeFile = promisify(fs.writeFile);
module.exports = async (src, dir) => {
if (/\.(jpg|png|git)$/.test(src)) {
await urlToImg(src, dir);
} else {
await base64ToImg(src, dir);
}
}
//url -> imgconst
urlToImg = promisify((url, dir, callback) => {
const mod = /^https:/.test(url) ? https : http;
const ext = path.extname(url);
const file = path.join(dir, `${Date.now()}${ext}`);
mod.get(url, res => {
res.pipe(fs.createWriteStream(file)).on('finish', () => {
callback();
console.log(file);
})
})
})
//base64 -> imgconst
base64ToImg = async function (base64Str, dir) { //data:image/jpeg:base64,/sssss
const matches = base64Str.match(/^data:(.+?);base64,(.+)/);
try {
const ext = matches[1].split('/')[1].replace('jpeg', 'jpg');
const file = path.join(dir, `${Date.now()}.${ext}`);
await writeFile(file, matches[2], 'base64');
console.log(file);
} catch (error) {
console.log(error);
console.log('非法 base64字符串')
}
}
-
使用OPENCV函数实现图像明亮度增强的直方图均衡化图像直方图均衡化是一种常用的图像处理方法,可以使图像的对比度增加,细节更加清晰。本文将介绍如何使用OPENCV函数来实现图像明亮度增强的直方图均衡化。
-
安卓视频编辑:Ffmpeg的应用随着智能手机的快速发展,人们对于拍摄和分享视频的需求也越来越大。在安卓系统中,有许多视频编辑应用可供选择。其中,Ffmpeg是一款功能强大的视频编辑工具,被广大用户认可并广泛应用。
-
如何在Anaconda中安装和使用OpenCVOpenCV(Open
-
OpenCV中resize函数的源码分析OpenCV是一个广泛使用的计算机视觉库,通过提供各种图像处理和分析功能,使得开发人员能够快速构建视觉应用程序。其中一个常用的函数是resize函数,它用于改变图像的大小。在本文中,我们将对OpenCV中的resize函数的源码进行详细分析
-
使用OpenCV编写数字识别函数OpenCV是一个开源的计算机视觉库,通过其丰富的功能和算法,我们可以实现许多图像处理和计算机视觉任务。其中之一是数字识别,通过OpenCV我们可以编写一个数字识别函数来自动识别图像中的数字。
-
C++中的future用法在C++中,future是一个非常有用的工具,用于处理异步任务和并发编程。它提供了一种在一个线程中计算结果,并在另一个线程中获取结果的方法。
-
使用FFmpeg处理二进制流FFmpeg是一个流行的开源多媒体框架,用于处理音频和视频数据。它是一个十分强大的工具,可以在各种平台上进行音频和视频流的编码、解码、转码和处理。本文将介绍如何使用FFmpeg来处理二进制流。
-
使用OpenCV实现人脸识别并显示扫描线在计算机视觉领域,人脸识别是一个重要的应用。人脸识别可以用于身份验证、安全监控、面部表情分析等多种场景。而OpenCV是一个常用的计算机视觉库,提供了丰富的功能和算法,可以帮助我们实现人脸识别。
-
OpenCV实现简单而高效的人脸识别技术OpenCV是一个广泛使用的开源计算机视觉库,其强大的功能和简单易用的接口使其成为实现人脸识别技术的首选工具。人脸识别技术在当今社会中越来越受到关注和应用,而OpenCV提供了一种简单而高效的方法来实现这一技术。
-
Java语言和Python语言的区别Java语言和Python语言都是目前非常流行的编程语言,它们各自具有不同的特点和用途。下面将从几个方面来探讨Java语言和Python语言的区别。
-
使用OpenCV和Python进行轮廓提取和图像抠图在图像处理领域,轮廓提取和图像抠图是非常常见和有用的技术。OpenCV是一个流行的计算机视觉库,提供了许多图像处理工具和算法。结合OpenCV和Python,我们可以轻松地实现轮廓提取和图像抠图的任务。
-
使用opencv进行图像识别OpenCV
-
使用ffmpeg命令添加水印FFmpeg是一个功能强大的开放源码多媒体框架,它可以用于编码、解码、转码、流媒体和多媒体处理等各种操作。在视频处理中,我们经常需要给视频添加水印,以保护版权或增加品牌曝光度。本文将介绍如何使用FFmpeg命令来给视频添加水印。
-
如何解决使用FFmpeg播放相机大分辨率时出现卡顿问题?在现代技术发展的今天,许多相机设备都配备了高分辨率的摄像头,以满足人们对更清晰、更真实图像的需求。然而,使用FFmpeg播放相机大分辨率时,有时会遇到卡顿问题,这给用户的观看体验带来了一定的困扰。为了解决这个问题,我们可以采取以下几个方法:
-
如何正确发音FFmpeg的英文术语?FFmpeg是一个广泛使用的多媒体框架,可以用来处理音频和视频文件。在学习和使用FFmpeg时,很多人会遇到一个共同的问题,那就是如何正确发音它的英文术语。
-
简体中文标题:将OpenCV人脸检测中小于faces.size() 的含义解释是什么?将OpenCV人脸检测中小于faces.size()的含义解释是什么?
-
如何优化OpenCV的CPU占用率OpenCV是一个广泛使用的开源计算机视觉库,用于图像处理和计算机视觉任务。然而,有时候在使用OpenCV时,我们可能会遇到CPU占用率过高的问题。这不仅会影响程序的运行速度,还可能导致系统负载过高。因此,对于那些希望提高OpenCV应用程
-
如何解决无法安装ffmpeg问题无法安装ffmpeg是一个常见的问题,可能由于多种原因导致。本文将向您介绍一些常见的解决方法。
-
使用OpenCV和PID控制实现摄像头控制在现代科技的推动下,摄像头的应用越来越广泛。然而,要使摄像头能够精确控制,需要借助一些先进的技术。其中,OpenCV和PID控制就是两种常用的技术。
-
开源光流法算法 - OpenCV光流法源码详解光流法是一种计算图像序列中像素运动的技术。在计算机视觉领域中,光流法被广泛应用于物体跟踪、动态分析和运动估计等任务中。而在实际应用中,OpenCV开源库提供了一种称为“OpenCV光流法”的算法,用于计算图像中的光流。
-
【简报】FFmpeg 黑群已更新至4.4.2版本近日,开源多媒体处理工具FFmpeg的黑群发布了最新的4.4.2版本。FFmpeg是一个功能强大的工具,可用于处理和转码多种音频和视频格式。黑群是FFmpeg版本的一个秘密分支,由黑客团队维护和开发。
-
OpenCV软件图标:简洁高效的视觉计算工具OpenCV(Open
-
Java计算机网络面试题:探索网络通信与Java技术的交集在当今数字化时代,计算机网络的重要性无需强调。无论是在个人领域还是商业领域,网络通信是实现信息交流和数据传输的关键。而Java作为一门广泛应用于软件开发领域的编程语言,其在网络通信中的作用也变得越来越重要。在Java计算机网络面试中,经常会
-
基于opencv的行人检测系统设计基于OpenCV的行人检测系统设计
-
Java语言培训班:帮助你掌握编程技能的最佳选择Java语言培训班是当今学习和掌握编程技能的最佳选择。无论你是想要提升自己的职业技能,还是新手入门编程,Java语言培训班都能够适应你的需求。
-
使用OpenCV实现图像增强算法OpenCV(开源计算机视觉库)是一个非常强大的工具,可以应用于图像处理和计算机视觉任务。其中之一的应用是实现图像增强算法,通过对图像进行预处理和改进,使其更加清晰、鲜明和易于分析。
-
OpenCV自动校正图像曝光不均问题OpenCV是一款广泛应用于计算机视觉的开源库,它提供了丰富的图像处理和分析工具。在图像处理中,曝光不均是一个常见的问题。曝光不均指的是图像中不同区域的亮度不一致,导致一些细节无法被准确捕捉到。
-
OpenCV实现图片缩放和旋转OpenCV是一个开源的计算机视觉库,它提供了丰富的功能,使我们能够在图像处理和计算机视觉方面进行各种操作。其中,实现图像缩放和旋转是使用OpenCV最常见的操作之一。本文将介绍如何使用OpenCV来实现图片的缩放和旋转。
-
基于OpenCV的人脸检测算法:一种快速高效的解决方案随着计算机视觉技术的快速发展,人脸检测已经成为了许多应用领域中必不可少的一项技术。基于OpenCV的人脸检测算法以其快速高效的特点成为了人脸检测领域的热门解决方案。
-
使用OpenCV在CSI摄像头上进行图像处理OpenCV是一个开源的计算机视觉库,用于实时图像处理和计算机视觉任务。CSI摄像头是一种高清摄像头,通常用于监控和安防系统中。本文将介绍如何使用OpenCV对CSI摄像头进行图像处理。
-
如何在FFmpeg中配置RTCP参数FFmpeg是一个开源的多媒体框架,用于处理音频和视频文件。在视频流传输中,RTCP是一种协议,用于监控和控制媒体会话的质量。在FFmpeg中,我们可以通过配置RTCP参数来控制和优化传输过程中的性能。
-
FFmpeg编码帧率设置:掌握技巧轻松实现高质量视频编码FFmpeg是一个开源的多媒体框架,可以用于处理音视频数据。在视频编码中,帧率是一个非常重要的参数,它决定了视频播放的流畅度和清晰度。掌握如何设置帧率,可以帮助我们轻松实现高质量的视频编码。
-
使用OpenCV和WebSocket实现图像传输和处理最近,随着图像处理技术的发展,人们对于图像传输和处理的需求出现了快速增长。为了满足这一需求,可以利用OpenCV和WebSocket来实现高效的图像传输和处理。OpenCV是一个开源计算机视觉库,可以提供丰富的图像处理功能。而WebSock
-
使用OpenCV进行游戏辅助-快速找图技巧分享在现代社会中,电子游戏成为了许多人放松和娱乐的首选。但是,有时候游戏中会遇到一些困难的关卡,这可能会让玩家感到沮丧。幸运的是,有一种名为OpenCV的计算机视觉库,可以帮助玩家在游戏中获得优势。本文将与大家分享一些使用OpenCV进行游戏辅
-
易语言与C语言接口的调用方法易语言(Easy
-
解决FFmpeg推流RTMP卡顿问题的方法在进行RTMP推流时,如果遇到卡顿问题,可以采用以下方法来解决:
-
OpenCV常用函数解析OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。它被广泛应用于图像处理、目标识别、物体跟踪、人脸识别等领域。本文将介绍一些常用的OpenCV函数,并对其功能进行解析。
-
如何使用FFmpeg生成音频频谱可视化效果音频频谱可视化是一种非常酷炫的效果,它可以将音频文件转化为可视化的图像。而FFmpeg是一款强大的音视频处理工具,可以通过它来生成音频频谱可视化效果。
-
使用 OpenCV 进行图像复原随着科技的发展,图像处理技术受到越来越多的关注和重视。在许多领域,如医学影像、电影制作和安全监控等,图像复原是一项重要的任务。使用
-
OpenCV模板匹配的缩放技巧OpenCV是一个功能强大的计算机视觉库,可以用于各种图像处理任务,其中之一就是模板匹配。模板匹配是一种在一幅图像中寻找匹配模板的技术,通过对比模板图像和待搜索图像的相似度来找出目标物体的位置。然而,在进行缩放时,模板匹配可能会面临一些挑战
-
OpenCV 5.0发布:更强大的图像处理功能近日,开源计算机视觉库OpenCV发布了最新版本的5.0。这个版本带来了许多令人振奋的新功能和增强的图像处理能力,为开发人员带来了更多的创作空间。
-
推荐的FFmpeg配置用于推流到RTMP视频流媒体技术的发展使得我们能够方便地通过互联网观看和分享视频内容。RTMP(Real-Time
-
OpenCV图像分割技术的应用和方法图像分割是计算机视觉领域中一项重要的任务,它被广泛应用于许多领域,如医学影像处理、工业质检、农业监测等。OpenCV是一个开源的计算机视觉库,提供了一系列图像处理和计算机视觉算法,包括图像分割。本文将介绍OpenCV图像分割技术的应用和方法
-
使用FFmpeg实时播放本地文件FFmpeg是一种广泛使用的开源多媒体框架,它提供了许多强大的功能,包括音视频编解码、转换、流媒体传输等。其中,实时播放本地文件是FFmpeg的一个重要应用之一。在本文中,我们将介绍如何使用FFmpeg来实现这一功能。
-
使用FFmpeg进行视频处理的模板FFmpeg是一个开源的音视频处理工具,可以在命令行中对音视频进行各种处理操作。它支持多种格式的音视频文件,并提供了丰富的功能和参数,使其成为一个强大的音视频处理工具。
-
Python 如何调用 FFmpeg 库Python
-
Java StopRecognition分词的用法指南Java
-
FFmpeg:全球最受欢迎的开源代码解析工具FFmpeg是一款全球最受欢迎的开源代码解析工具,广泛应用于音视频编解码、转码等领域。它的灵活性和强大的功能使得它在众多领域中都有广泛的应用。
-
OpenCV 移动端:图像处理与计算视觉的强大工具在当今移动应用开发领域,计算机视觉技术的应用越来越受到重视。而在计算机视觉技术的背后,有一个强大的工具被广泛使用,那就是OpenCV。
-
学习使用FFmpeg一步步实现悯农主题视频在现代社会中,视频已经成为人们日常生活中不可或缺的一部分。人们通过观看视频来获取信息、娱乐和交流。而制作一个令人难忘的视频则需要一些专业的工具和技巧。本文将介绍如何使用FFmpeg一步步实现悯农主题视频。
评论区